計算が遅いぞ
だんだん,あなたの計算に時間がかかるようになってきました.対策が必要です.
- そもそも, MacBookPro/Airは, スターバックスでコーヒー飲みながらサイトとかを編集すると快適なように製造されている.
- 決して数値解析やフルサイズの映画編集が高速なようには設計されていない.
- だからMacBookNeo/Airで数値計算するのは, あくまでもテストであって,本当の計算はLinuxの計算サーバーで行う. 無理すればMacbookAirでも可能だが,まあ,変人だろ.
- いままではC++の学習に焦点を合わせてきた.実際の解析では「最適化」しないとだめだ.
- 2026年現在,高速計算は「並列計算」が必須であって,それを学ばねばならない.
計算時間の計測
で,計算が遅いとか早いとか雰囲気で述べても仕方がないですよね.「この計算に23.44msec必要」と議論する必要があります.それはここでインストールしたBoostが便利です!
CPUTIME 測定例
例えばあなたのプログラムが
...
int main(){
SigmaSolver solver;
solver.run();
}であったとき, AIに「solver.runに必要な時間をboostで測定しやがれ」と要求すると, まあこんな感じに:
...
#include <boost/timer/timer.hpp> ... int main(){ SigmaSolver solver; // CPU時間の計測開始 boost::timer::cpu_timer timer; solver.run(); timer.stop(); // 計測結果を表示 std::cout << "=== CPU Time ===" << timer.format() << std::endl; return 0; }
で, Boostを使うのですからCMakeLists.txtも変更が必要です. CMakeLists.txtを見ながらAIに「おいらのPCでBoost使えるようにしてよ」と要求すると
CMakeLists.txt: ... set(CMAKE_CXX_STANDARD 17) set(CMAKE_CXX_STANDARD_REQUIRED ON) set(CMAKE_CXX_EXTENSIONS OFF)
add_compile_options(-I/usr/local/include) find_package(Boost REQUIRED COMPONENTS timer chrono)
include_directories(${Boost_INCLUDE_DIRS}) ... add_executable(step1 src/step1_calc_sigma.cpp) ←step1があなたのプログラムだとすると target_link_libraries(step1 ${Boost_LIBRARIES}) ←これがつく ...
最適化
では, まずはMacで最適化を行なってみましょう. あなたのプログラム(以下の例では step1)を最適化したいとします. CMakeLists.txt を見ながら, AIに「step1の実行が遅いぞ」と要求すると,以下の訂正が行われました:
CMakeLists.txt: ... add_executable(step1 src/step1_calc_sigma.cpp) if (CMAKE_CXX_COMPILER_ID MATCHES "Clang|GNU") target_compile_options(step1 PRIVATE -O3) ←まあ要するに -O3 をつけると最適化が行われる endif() ...
では実行してみましょう!
arm64% ./step1 Iter 0: max_diff = 0.5 === CPU Time === 66.720000s wall, 66.460000s user + 0.120000s system = 66.580000s CPU (99.8%)
walltimeってのは, あなたの部屋の壁に存在する時計の針の移動量(つまり実時間), usertimeってのは, ユーザー(あんたのことだ)が使ったCPU, systemtimeってのはMacOSが使った時間です. なるほど, 2025年製M4でも66.5秒かかってますねえ.
計算の速度はマシンで変わる
実は,数値計算の速度は,計算機によって変わります.いろいろなマシンでやってみました
| MacbookAir | 2016年製FS | 2020年製FS | 2015年製ノード | 2020年製ノード | |
|---|---|---|---|---|---|
| name | おれの | sun0 | sun1 | is2015-4 | as2020-3 |
| year | 2025 | 2016 | 2019 | 2015 | 2020 |
| CPU | M4 | Xeon E3-1245 V5 | Xeon Silver 4216 | Core7 5930K | AMD Threadripper 3970X |
| コア数 | 8 | 4 | 16 | 6 | 32 |
| time | 66.5 sec | 67.1 sec | 122.2 sec | 141.3 sec | 62.3 sec |
んー,どれが速いのか, よくわからんな. まあしかし,うちもお金ないから,ちょっと古いマシンだらけになってきたな
sun1が遅いな?と思ったら, 計算中だったwww ギリシャ旅行中にジョブ撃つ学生がいるのは想定外だ
並列計算とは
では,本題の「並列計算」最適化を行いましょう! 最近のPCには,計算作業をおこなう「CPU」とか「コア」というものがたくさん付いているので, 同時並行で計算すれば速くなる,わけです
まあ, あなたの口でお刺身一切れ食べるのに0.5秒かかる時, 口を16個に増設したら, 32切れ/secで刺身を処理可能!というわけです.
実際には そんなに 簡単じゃなくて
刺身を食べる口の数(コア数)を増やしただけで,本当に高速に刺身が食べられるのか?は問題です.普通の人間でそんなことしたら,口(CPU)から消化器官(メインメモリ)への食道(メモリーバンド幅)が不足してしまい,口に入れた刺身が胃袋に入ることができず
・・・れろれろれろ・・・
って感じになります.食道の数も増設しないと!もちろん消化器官も増設して8個!でも,そうしたら,消化器官を稼働するのに必要な血流(消費電力)が増大してしまい,貧血で倒れてしまう(電流不足でPCがダウンする)ようになります.仕方がないので心臓も4個くらいに増設!それでも,肛門(最終データを吐き出すディスク装置)のサイズが不足してしまうと,排泄できないので消化器官が詰まり, 食道が詰まり・・・
・・・れろれろれろ・・・
やはり肛門の直径は20cmくらいにしとかないと, 秒速32個以上で刺身を食べることは難しそうです.
なので,結局,必要なのは「トータルバランス」なんですね.で,こうやって,違和感のある生物になったものが.「計算ノード」です
並列化にもいろいろあって
パラメータ並列化
計算作業が,大まかに,いくつかの独立なグループに分けられる場合には,その作業全体を並列化すると効率が良いです.
- ある方程式系を, 100000通りの初期値について, 全部計算したい.単に100000ケース独立に解くだけである.
例えば確率論的な計算手法--例えばDSMC--で時間発展を追跡する時には, 粒子の初期配置10000000通りについて解析し,最終結果の平均をとります.すると・・・10000000回プログラムを実行することになるのですが,それは無理なので,それを1つのプログラムで済ませるイメージです.これは,別のところで説明しましょう.
領域並列化
例えば,物体の上の流れ場と,下の流れ場に分かれている,のように,計算作業が「領域」に分かれている場合に,領域別に並列化を行う
これは,あとで説明しましょう.
タスク並列化
例えば, あるデータに「微分を行わねばならぬ」「だが積分も行わねばならん」のように独立並行した作業がある場合,作業別に並列化を行う
これは,別のところで説明しましょう.
ループ並列化
for(int i=0;i<10000;i++)みたいなループを並列化します.ここでは, これを説明しましょう.
OpenMP並列化
並列化できるループと,並列化できないループ
ループには,並列化できるやつと,並列化できないやつがあります.それを見分けるのは次のルールで十分:
for(int i=0;i<10000;i++)では,i=0の後にi=1で, 次にi=2,,,の順番で行うことになっているが, これをランダムな順番(i=512の次にi=23やって, 次にi=9234とi=14を同時に,など)で行なって良い場合,並列化できる.
具体例
ここで学んだ差分計算でも,並列化できるのとできないのがあります.
陽的差分法では,
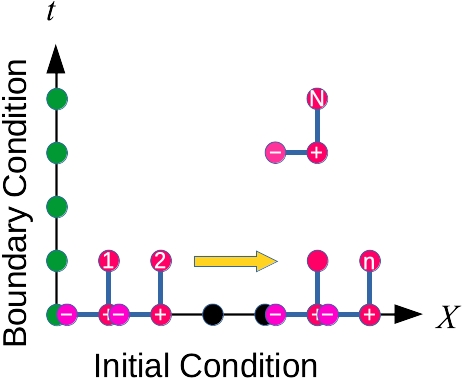
これを 23, 4, 5, 1,... の順に計算しても問題ないです.しかし, 陰的差分法
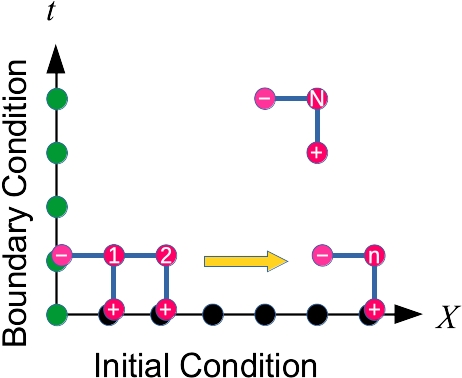
これを, i=2 の次にi=1を計算すると,間違いになりますよね!これは,並列化できないです.他にも,ここで学んだ積分はみんな
double sum=0.0;
for(int i=0;i<N;i++)
{
sum=sum+f[i]*w[i];
}
という形になってますよね. これは,
sum=0.0;
sum=sum+f[123]*w[123] , sum=sum+f[12]*w[12]
を同時に実行すると, sumの値はf(123)*w(123)になるのか?f(12)*w(12)になるのか?はたまたf(123)*w(123)+f(12)*w(12)になるのか?わからないです.
なので,基本的には並列化できません.
並列化できないループでも,知恵と工夫次第で並列化できる場合がありますので!諦めてはいけないです.
例えば
double sum=0.0;
...
for(int i=0;i<array.size();++i)
{
...
sum=array[i]+....; 何か計算
...
array[i]=...sum....;
}
これは並列化できないですよね! ここでsumを計算して, ここで使うまでの間に, 同時平行に別の i の値を計算している人が, sumの値を変更してしまう可能性があるからです!でも, これは
...
for(int i=0;i<array.size();++i)
{
double sum=0.0;
...
sum=array[i]+....; 何か計算
...
array[i]=...sum....;
}
こうするだけで, 並列計算可能になります! ここの部分で, 「該当のiの値に専用のsumを用意」しているので, ここで専用sumを計算して, ここで専用sumを使うまでの間に, 別の i の値を計算しているCPUに邪魔をされないからです.
まあ要するに
- プログラム全体とかクラス全体で見える変数へのアクセスが要注意!同時に書き込む可能性があるから
- 可能性を減らし,分かりやすくするには,「変数は直前に定義せよ」「プログラムの先頭で変数を定義するな!」
ということです.
並列化できないループを,無理やり並列化することは,問題なくできてしまいます!そこが大きな問題で,あなたが「並列化できる/できない」を間違えると,計算機の方から「間違ってますよ」と言われることは決してありません. もちろん,結果は大間違いです.その責任は,判定を間違えたあなたにあります!そこは,そこだけは!注意してくださいね.
サンプル
サンプルのプログラムは, 基本的にはこんな感じです:
for(int i=0;i < array.size(); ++i)
{
double sum=0.0;
for(int j=....)
for(int k=....)
{
v=V[j][k];
....
sum+=...some value...
}
array[i]=sum;
}
で,計算方法をよくみた結果, ここのiのループは並列化できる. ここのj, kループは sum が引っかかって並列化できない.となりました.それぞれを, 並列化してみましょう.
単純な i ループで並列化
該当のループを示しながら,AIに「このiのループ並列化してね」とお願いしましょう!
...
#include <omp.h> ←ループの並列化は, 専門用語でOpenMPと言います. OpenMPをする時にはこれが必要
...
#pragma omp parallel for schedule(dynamic) ←並列化するループの前に, これを入れるとOK
for(int i=0;i < array.size(); ++i)
{
double sum=0.0;
for(int j=....)
for(int k=....)
{
v=V[j][k];
....
sum+=...some value...
}
array[i]=sum;
}
OpenMPを使う場合には, CMakeLists.txt を変更する必要があります. が, まあAIが先回りで変更しておいてくれているはずです:
CMakeLists.txt:
...
find_package(OpenMP REQUIRED)
if(OpenMP_CXX_FOUND)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
endif()
...
target_link_libraries(step1 ${Boost_LIBRARIES} OpenMP::OpenMP_CXX)
...
では, 実行しましょう! MacBookAirはOpenMPに対応してないし, 対応したところで大したことないので, もちろん, Linuxで実行します:
arm64% ssh sun0
sun0$ cd そのフォルダ
sun0$ mkdir build
sun0$ cd build
sun0$ cmake ..
sun0$ make step1
sun0$ ./step1
実行中に, ここで紹介したtopコマンドを見てみましょう:
Tasks: 307 total, 2 running, 305 sleeping, 0 stopped, 0 zombie
%Cpu(s): 99.5 us, 0.1 sy, 0.0 ni, 0.2 id, 0.0 wa, 0.1 hi, 0.0 si, 0.0 st
MiB Mem : 63804.9 total, 3886.8 free, 5911.1 used, 54886.1 buff/cache
MiB Swap: 32096.0 total, 29265.5 free, 2830.5 used. 57893.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1415268 sugimoto 20 0 63660 6360 3968 R 794.4 0.0 0:42.30 step1
1592 dirsrv 20 0 3397228 100076 67328 S 0.7 0.2 3440:20 ns-slapd
...
これがあなたの計算で, 注目するのはこのCPU%です. sun0は4コアで8並列計算が可能なので, 800%近くになってますね!こうなってれば, 一応,少なくとも形式的には並列計算できています,
- 実際に計算が高速になってないと,実質的に並列計算できているとは言えないです.
例えばas2020-3で実行するとこんな感じ
as2020-3 $ ./step1
Iter 0: max_diff = 0.5
CPU Time: 1.680000s wall, 100.840000s user + 0.000000s system = 100.840000s CPU (6002.4%)
まず, walltimeは 1.68 secで, 実時間が 62秒 → 1.7 秒に36倍の高速化してます! usertimeは 62秒 → 100 秒に増加していますorz.. 並列計算は無料ではなくて
- #pragma omp parallel for までは 1CPUで実行してた
- お!#pragma omp parallel for だ!他のCPUを占領開始(スレッドの作成,といいます)!
- 他のCPUを占領したので実行コード転送
- 並列計算開始!
- ループ終わったので占領終わり
- 続きを実行
となりますので,赤字部分が無駄になって, CPU使用時間は増えるんですよね... 要するに, 「一個の i=23 とかで実行する計算量が少ないと,赤字の部分だらけになって率が上がらない」ということになります. 作業量が少ないままでスレッド数だけを増やすと,かえって遅くなったりします.ええっと32コアのマシンで, この会社のCPUは1コアで2スレッド走るので64並列になるはずですが,ここを見ると60個ぐらいしか実際に効いてねえことがわかる. で, 並列化効率が大したことないので,実時間は36倍速にしかならなかった.ま,こういったところが,あなたの腕の見せ所,なわけです.
| MacbookAir | 2016年製FS | 2020年製FS | 2015年製ノード | 2020年製ノード | |
|---|---|---|---|---|---|
| name | おれの | sun0 | sun1 | is2015-4 | as2020-3 |
| year | 2025 | 2016 | 2019 | 2015 | 2020 |
| CPU | M4 | Xeon E3-1245 V5 | Xeon Silver 4216 | Core7 5930K | AMD Threadripper 3970X |
| コア数 | 8 | 4 | 16 | 6 | 32 |
| 1CPU time |
66.5 sec | 67.1 sec | 80.9 sec | 141.3 sec | 62.3 sec |
| parallel time |
14.2 sec(8) | 5.0 sec(32) | 23.9 sec(12) | 1.72 sec(64) |
んー,古い計算ノードよりも, Xeonでできているファイルサーバーの計算速度が大きいところが笑えるが. さらに, 古いsun0の方がクロック3.9 GHzで, sun1は3.2 GHz なので, 1CPUだとsun0が速く, N-CPUだと sun1 が速いのだ. このように,実際の計算時間って,結構複雑なんですよね.
計算の速度はthread数で変わる
ということは. 並列化の数を調整した方が多少速くなる可能性は, 僅かにある.デフォルトでは「使える並列数の最大」になってますので, それが最適なのかは, 不明です. thread数を指定して実行するには
方法1 is2015-4% OMP_NUM_THREADS=6 ./step1
方法2 is2015-4% export OMP_NUM_THREADS=6
is2015-4% ./step1
まあ2行になっているのかどうか,だけですが. 色々変えてみた. 6Core, 12Threadsのマシンだと
| thread数 | 1 | 2 | 4 | 6 | 8 | 10 | 12 |
|---|---|---|---|---|---|---|---|
| wall time |
144.0 sec | 73.6 sec | 37.5 sec | 25.0 sec | 24.7 sec | 24.4 sec | 24.3 sec |
もちろん, 結果は貴方のループの長さ,計算種類に強く依存するので, 自分で調べてくださいね.
クソな j,k ループで並列化
サンプルプログラムの,jループとkループは, 2重ループなので, そもそもが並列化できないです.ですがよく見ると, プログラムは:
for(int i=0;i < array.size(); ++i)
{
double sum=0.0;
for(int j=....)
for(int k=....)
{
v=V[j][k];
....
sum+=...some value...
}
array[i]=sum;
}
黄色部分以外には j, kが登場していなかったとします. こういうことなら, 2次元配列 V[j][k] を1次元化してしまえばよろしい. ここで作成したmyArrayクラスは, 実はこういう並列計算に便利なように作ってあるのです. さて問題は V[j][k] の定義ですが,まあ例えば
int N=10,M=20;
---パターン1
double V[N][M];
---パターン2
std::vector<std::vector<double>> V(N,std::vector<double>(M));
などと定義されているでしょうね. これをmyArrayに置き換えましょう:
#include "myArray.hpp"
...
class myElement
{
public:
double value;
};
myArray<myElement> V(N,M); ←まあmyElementのところはdoubleでもOK
...
ここいらで V(i,j)の値を設定
...
for(int i=0;i < array.size(); ++i)
{
double sum=0.0;
for(int j=....)
for(int k=....)
{
v=V(j,k);
....
sum+=...some value...
}
array[i]=sum;
}
もしこれで動くのであれば, 赤色の部分は
for(int i=0;i < array.size(); ++i)
{
double sum=0.0;
for(int j=0;j<V.size();j++)
{
v=V[j];
....
sum+=...some value...
}
array[i]=sum;
}
でも動作します. で, ここのループも1重ループになったので, 並列化できます!こういうのを,多重ループの1獣化といって,定番の方法です.
・・・でも,上のサンプルでは, このsumにこの足し算で多数のtheadのアクセスが競合して,並列化できないです.ところが, こういう計算が含まれるケースは非常に多く,これまた,定番の回避方法が用意されています.
for(int i=0;i < array.size(); ++i)
{
double sum=0.0;
#pragma omp parallel for reduction(+ : sum) schedule(dynamic)
for(int j=0;j<V.size();j++)
{
v=V[j];
....
sum+=...some value...
}
array[i]=sum;
}
計算してみると
| MacbookAir | 2016年製FS | 2020年製FS | 2015年製ノード | 2020年製ノード | |
|---|---|---|---|---|---|
| name | おれの | sun0 | sun1 | is2015-4 | as2020-3 |
| year | 2025 | 2016 | 2019 | 2015 | 2020 |
| CPU | M4 | Xeon E3-1245 V5 | Xeon Silver 4216 | Core7 5930K | AMD Threadripper 3970X |
| コア数 | 8 | 4 | 16 | 6 | 32 |
| 1CPU time |
66.5 sec | 67.1 sec | 80.9 sec | 141.3 sec | 62.3 sec |
| i parallel time |
14.2 sec(8) | 5.0 sec(32) | 23.9 sec(12) | 1.72 sec(64) | |
| j parallel time |
14.8 sec(8) | 5.3 sec(32) | 23.6 sec(12) | 1.76 sec(64) |
大して変わらんなあ.
MPIを用いた並列化
領域分割とは
次のようなサンプルプログラムを考えてみます:
...
std::vecotr<myData> Data;
...
for(int i=0;i < array.size(); ++i)
{
double sum=0.0;
for(int j=0;j<V.size();j++)
{
v=V[j];
....
sum+=...Dataを用いた何かの計算...
}
Data[i]=sum;
}
計算
..
.
.
.
.