管理サーバー
いろいろ試行錯誤した挙句,要するにこうだ.はじめてのユーザーに伝えるべきことは
- Slurmは, 管理サーバー slurmcltd がユーザーのジョブを受け取り,実行サーバー slurmd に実行してもらいます.
- 管理サーバー slurmcltd はジョブを管理しているだけなので, 特権ユーザーである必要はありません.
- ユーザー slurm グループ slurm にしておくのがセキュリティ上安全です.だからさっさと作れ
- /bin/mail が必要なので, mailx パッケージみたいなのインストールしとけタコ
- 実行サーバー slurmd は,各ユーザーの権利を管理する必要がありますので, 特権 root で動作します.
よって,管理サーバでは,いくつかのフォルダーをあんたが準備する必要がございます. 所有者 slurm.slurmです.
| /var/spool/slurmd/ | 作業中のジョブを保存します |
|---|---|
| /var/slurmd/ | 管理サーバーの状態を保存しています. |
| /var/run/slurm/ | systemdで管理サーバーの情報を保存します |
必要な設定ファイルは(インストール時の設定にもよりますが)次の通り:(★管理サーバ☆計算ノード)
|
/etc/ld.so.conf.d/slurm.conf ★☆ |
共有ライブラリーのための設定ファイル. ライブラリの場所を書く: /usr/local/lib |
|---|---|
|
/etc/tmpfiles.d/slurm.conf ★ |
/var/run はtmpfsで再起動でクリアされてしまいますので, フォルダーを準備する. なお /var/run は /run のシンボリックリンクであることに注意 d /run/slurm 0770 slurm slurm |
|
/usr/lib/systemd/system/slurmctld.service ★ |
systemdで起動するためのファイル. 自動的にはインストールされないので注意(パッケージの etc/ フォルダーに落ちている) . |
| /usr/lib/systemd/system/slurmd.service ☆ | systemdで起動するためのファイル. 自動的にはインストールされないので注意(パッケージの etc/ フォルダーに落ちている) . |
| /usr/local/etc/slurm.conf ★☆ | システム構成ファイル. 下で述べる. |
| /usr/local/etc/cgroup.conf ☆ | LinuxのCgroupに関するなにこれ設定(パッケージの etc/ フォルダーに落ちている) . |
構成ファイル設定
よい子は,初めて起動する前に,構成ファイルをシステムに応じて記述します. 今まで一度もよい子ではなかった人も,ここでは,よい子にした方が良いです.全体にわたる設定について書く:
# /usr/local/etc/slurm.conf SlurmctldHost=h225 お前のサーバーのhostname -sで出るやつ SlurmUser=slurm サーバーを実行するひと # Ports SlurmctldPort=6817 これ,要るのか知らん SlurmdPort=6818 しらねえって # Folders SlurmctldPidFile=/var/run/slurm/slurmctld.pid systemdのserviceファイルに書いたよね? SlurmdPidFile=/var/run/slurmd.pid systemdのserviceファイルに書いたよね? SlurmdSpoolDir=/var/spool/slurmd StateSaveLocation=/var/slurmd # Cgroup ProctrackType=proctrack/cgroup # New Node Action Failした計算ノードの取り扱い(自動復帰か,落ちっぱなしか) ReturnToService=0 ClusterName=FDLAB # Scheduling SchedulerType=sched/backfill SelectType=select/cons_res SelectTypeParameters=CR_Core
続けて,計算ノードについて書く.
CPUの数や搭載メモリー量,テキトーに書いたらバレる
登録する前に,嘘書くとバレるので,計算ノードのスペックを調べると良い.以下のものが必要である.
| Sockets | マザー板上に半田付けされている,でかいICを嵌めるバネつきのゲジゲジの数 |
|---|---|
| CoresPerSocket | IC入れる穴に,石ころやらバナナを詰めるわけだが,一粒あたりのCoreの数. /proc/cpuinfo で言うところのCPUですね. |
| ThreadsPerCore | Coreで走れるスレッドの数.BIOSで設定できるよね.砂利では1だな. |
| CPUs | システムにより, Coreの総数あるいはThreadの総数となる. そうだ. |
| RealMemory | 本当に搭載しているメモリーをメガバイト単位で |
いやそんな知らねえよ,てのが普通ですよね.計算ノードで,次のコマンドで調べます
# /usr/local/sbin/slurmd -C NodeName=h225 CPUs=2 Boards=1 SocketsPerBoard=1 CoresPerSocket=2 ThreadsPerCore=1 RealMemory=3937
嘘書くとゴネ始めて結構面倒なので,真面目に書きましょう. スペックとしては, 他に
- Feature=noroma,gomi 計算ノード選択に役立つ文字列をコンマで複数指定可能です.
- Gres=gpu:K20:2,gpu:K40:1 計算ノードに固有のリソースをコンマで複数指定可能.
計算ノードの宣言はこんな感じ
NodeName=登録名[範囲] NodeHostname=正式名[範囲] NodeAddr=IPアドレス マシンスペック
正式名はhostname -sで得られる名前と一致していなければならない. 登録名がNodeHostnameと同じならば, 正式名NodeHostnameは省略可能である.登録名, 正式名として範囲指定が利用できる.つまりh[192,201-220] では, h192, h201,h202,...,h220 を宣言することになる.
NodeName=mynode[1,2,4-5] NodeHostname=h[225,226,228-229] これはOK NodeName=mynode[a,b,d-e] NodeHostname=h[225,226,228-229] これはだめ
IPアドレスは,純粋な計算ノードで,IPアドレスが正式名からDNSで得られるならば省略できる.計算ノードが管理サーバーと同じものであれば,ローカルホスト127.0.0.1を記入する必要がある(外部のマシンであると誤認し外部アクセスを試みてしまう). マシンスペックは,上で取得したものを入れておけば良い.
例えばこんな感じですね:
NodeName=ib2007-3 NodeHostname=h225 NodeAddr=127.0.0.1 CPUs=2 RealMemory=3936 Sockets=1 CoresPerSocket=2 ThreadsPerCore=1,Feature=noroma,Gres=gpu:K40:0ジョブクラスを定義
ジョブクラスは,優先度や継続時間によって複数定義するものですが,まずはテスト用に一つ定義します.例えば
PartitionName=f3h Nodes=ib2007-3 State=Up MaxTime=0-3:05:00
ここでは,クラス名 f3h, 継続時間が0日3時間5分のジョブクラスを定義しています.参加ノードは,登録名がib2007-3の計算ノード(実は管理サーバ)です.
起動
一台のサーバー機で,管理サーバーを起動
# systemctl start slurmctld全ての計算ノード(必要ならサーバー機でも)で,ノードサーバーを起動
# systemctl start slurmdslurm.conf を書き換えた後は,再読み込み:
# scontrol reconfigureさてさて.状況を見てみる:
# sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
f3h up 3:05:00 1 idle ib2007_3
オーケーだ.にゃお,STATEの意味は:
| ALLOC | 先約あり | ALLOCATED | 先約あり |
|---|---|---|---|
| COMP | 絶賛計算中 | COMPLETING | 終了処理中 |
| DOWN | 死んでる・・・ | DRAIN | 気分が悪い |
| FAIL | 堕ちた | IDLE | 暇してる |
| MAINT | 修理してる | POWER_DOWN | 切れてる |
一度落ちると,自動では復活しない.
# scontrol scontrol: update NodeName=h225 State=IDLE Reason="OKOK Ure OK all right ?" scolnrol: quit
これで治る.
ジョブ投入
ではジョブを投入してみる. ジョブ文は
first.job: #!/bin/bash #SBATCH -p f3h #SBATCH -o myjob.stdout #SBATCH -e myjob.stderr #SBATCH --job-name="MyFirst..." pwd sleep 300
では投入:
$ sbatch first.jobすると実行が始まる
$ squeue -l
JOBID PARTITION NAME USER STATE TIME TIME_LIMI NODES NODELIST(REASON)
5 f3h MyFirst. sugimoto RUNNING 0:13 3:05:00 1 ib2007-3計算機が全て使用中になっちまった:
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
f3h up 3:05:00 1 alloc ib2007-3クライアントノード
クライアントノードを作成してみる.あり?slurmのconfigureがmungeが見つからないと言っている. dnf でインストールしたのに・・・なぜ?お?こいつはincludeファイルを探しているのか・・・困ったな.
git clone https://sugimoto605@bitbucket.org/rgdkyotou/thirdparty.git # ここでMakefileのSLURMサーバーアドレスを設定する make munge.key.copy 計算ノードではサーバーで使っているキーをコピー scp 10.249.229.225:/local/packages/thirdparty/rc/munge.key rc/ Password:いつもの # ここで slurm-19.05.4.tar.bz2 をネットで探し出して CLUSTER/BASE にコピー make slurm-client # ここで /usr/local/etc/slurm.conf で良いか,目視で確認せよ systemctl start slurmd
で,稼働を確認した. 試しにたくしゃん入れよ.面倒やし連打爆撃
$ squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 10 f3h MyFirst. sugimoto PD 0:00 1 (Resources) 11 f3h MyFirst. sugimoto PD 0:00 1 (Priority) 12 f3h MyFirst. sugimoto PD 0:00 1 (Priority) 13 f3h MyFirst. sugimoto PD 0:00 1 (Priority) 14 f3h MyFirst. sugimoto PD 0:00 1 (Priority) 6 f3h MyFirst. sugimoto R 1:01 1 ib2007-1 7 f3h MyFirst. sugimoto R 0:33 1 ib2007-1 8 f3h MyFirst. sugimoto R 0:30 1 ib2007-3 9 f3h MyFirst. sugimoto R 0:30 1 ib2007-3 $ sinfo -Nl NODELIST NODES PARTITION STATE CPUS S:C:T MEMORY TMP_DISK WEIGHT AVAIL_FE REASON ib2007-1 1 f3h allocated 2 1:2:1 3935 0 1 kuzu none ib2007-2 1 f3h down* 2 1:2:1 3935 0 1 noroma Not responding ib2007-3 1 f3h allocated 2 1:2:1 3935 0 1 kuzu none ib2007-4 1 f3h down* 2 1:2:1 3935 0 1 noroma Not responding
やっほう.コアが2つって,今から考えるとさみしいね〜.やっぱ何十個かないとつまらん.
slurm.confを苛めてみる
疑問だ.Torque/PBSでは
- 計算ノードの設定ファイルには, 「お前の親分はこのマシン」しか書かない
- 管理サーバーの設定ファイルに,ジョブクラスだの他の設定が全部書かれる
一方,Slurmでは全設定を書いた slurm.conf を,管理サーバー・計算ノードで共有せよ.ということなのだが.
- いや・・・そんなもん,そのうち,1台くらい,なんか古いファイルつかったノード
とか出てくるのは避けられない.大事故が起こる前に,ありがちな事故は発生させよう.
とりあえずわかっていることは
- slurmdは, 起動するときに, slurm.conf のケツの方のNodeNameとPartitionから,自分の場所を探す.
つまり, NodeNameの宣言は,さすがに計算ノードでも必要である.
管理サーバーが勝手にPartition設定を変えたらどうなる?
試してみた.計算ノードが生きたまま,そのpartition設定を管理サーバーで変更し,
# scontrol reconfigureすると?おや.計算ノードでもついてくるな. ジョブも実行できるね.
つまり,計算ノードは, Partition設定を見ていない.サーバーが,これやれよ,と言ったものをやる.
管理サーバーが勝手に計算ノードを増やしたらどうなる?
クライアントが勝手に一台増えた. 管理サーバーに連絡するのが面倒なので,とりあえず計算ノードでクライアントをインストールし,勝手に起動してみると,無事に起動する.しかし,どのPartitionにも参加していないので,せっかつ追加した計算ノードを利用することはできない.
仕方がないので,管理サーバーでも, その新しいノードを記述して reconfigure してみた.すると無事に認識され, Partitionにも入る. ジョブも正常に実行され,問題はない.と,いうわけで
- 管理サーバーの slurm.conf には,全ての計算ノードの定義,全てのPartitionの定義が必要
- 計算ノードの slurm.conf は,全体的な設定は管理サーバーと一致する必要がある.
- ノードについては,自分のNodeNameが定義されていれば十分
- ノードの slurm.conf には,Partitionの設定は不要
じゃあ共有するほどのものではないな.計算ノードでは,インストール時に,まあ自分だけが記載されている一発を持ってれば十分なのだ.必要なのは,管理サーバーやログファイルの名前,ポート番号くらいですな.
ジョブスケジュールSCHED
RMSの基本機能は,ある仕事が終わったら自動的に次の仕事を行う,です.有名店にお客が列をなしている,ってイメージです.基本,みんな平等に並びます(貴族や金持ちが平民を追い越して優先的に入るってのは「優先度」の概念です).これはスケジューラが行います.Slurmのデフォルトはバックフィルで,全体設定で決定:
SchedulerType=sched/backfillsched/backfill 各ジョブ文の申請使用時間を見て,隙間に入りそうな奴は入れて総時間を最小にしようと足掻く
チュートリアルによると,要するにこうだ
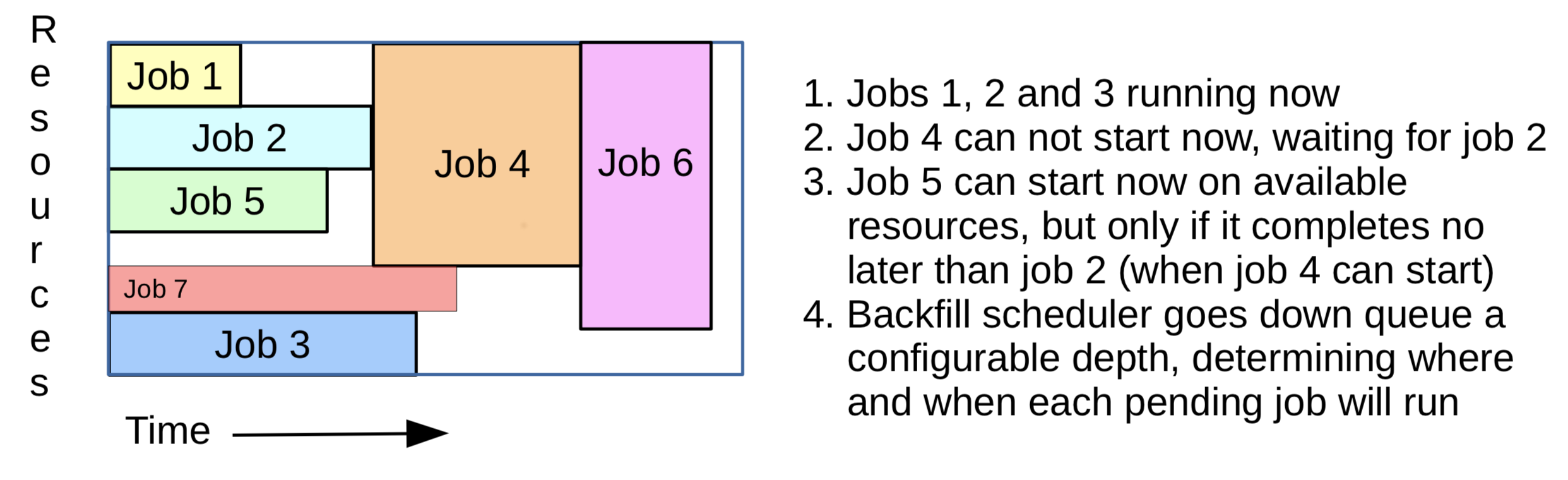
????/fairshare 各ユーザーの過去の使用時間を見て, 平等感を演出. サポートされていないのかも?不明だ
計算資源SELECT
計算資源の割り当て方法も全体設定で決める.例えば
SelectType=select/cons_res SelectTypeParameters=CR_Core
select/linear
(デフォルト)ううん?多分1ノードに1ジョブってことなのかな.
select/cons_res
資源が許せばジョブを入れる.1ノードで複数のジョブが実行され得る.あるジョブが計算機のIOを使い切ったりすると,他方のジョブが影響を受ける可能性がある.
CR_Core 資源とは, CPUのコアのことである.
CR_CPU 資源とは, CPUのことである.
CR_Memory 資源とは, メモリーのことである.
CR_Core_Memory 資源とは, CPUのコアとメモリーのことである.
CR_CPU_Memory 資源とは, CPUとメモリーのことである.
slurm.conf のマニュアルがひどく読みにくい理由がわかった.属性を説明するときに,それが「全体の」属性であるのか,「ジョブクラス」の属性であるのか,「計算ノード」の属性であるのかを,示していないんだ.だから,そもそも,なんの話をしているのかのベースが不明なので,いくら細かく書いても意味不明で読みにくい・・・
逆に言えば,読み手が,そこを補えば,解読可能だ.
こころで,宣言したメモリー量を超えて使おうとすると,何が起こるのかなあ?もしかして死を賜るのかな?
ジョブ優先度
ジョブには優先度を設定することができる(Ttorqueのjobclass,ですね). 優先度は次の要素から構成されます
- 差別(エコノミーよりもビジネス,それよかファーストクラスが優先して席に座るってやつ)
- 弱肉強食(弱いジョブが走ってたら,後から来た強い奴に踏んづけられ,強い奴が先に走るやつ)
- 仕事なのだから優先順位,時間スパンってのがあるのよね
- 束縛(計算時間が切れたら止まっちまうやつ.メモリー・ディスクはTorqueでは困難で結局できなかった)
- 巨大メモリープログラムをわざわざメモリーの小さいマシンで走らせて,「僕の計算って大変なんですよ〜」て偉そうにしてた奴がいたなあ・・・CPU使用率が0.2%以下だったが
- 通信が遅いと思ったら,計算時間の99%をリモートディスクのアクセスに使ってた奴もいたな.
- 計算時間制限しないと,「それ,いつ終わるの?」「知るわけないじゃないですか」というのが普通で常識的になってしまう
うむ.全部必要だ.どうやって設定するのだ?
弱肉強食の実現
Preemption(やばくなったら,ずらかる)を利用する.これは全体設定
PreemptType=preempt/partition_prio
PreemptMode=SUSPEND,GANG
で決定される.
preempt/none
もちろん何も起こらない
preempt/partition_prio
ジョブクラスPartitionの属性 Priority に応じてやば加減を検出.もちろん,あるノードが複数のPartitionに属してないと無意味.
preempt/qos
何かのQuality Of Serviceに応じて Preemption を行う.何の品質に,どのサービスか,謎に包まれている
やばくなったときの行動をPreemptModeで設定しなければならぬ. これは全体設定に応じて,各ジョブクラスに別の値を指定できる.
PreemptMode=OFF なんで俺がどかなあかんのや?どくわけないやろ?と宣言
PreemptMode=SUSPEND SIGSTOPでおねんねする. 高貴な方々がいっちまったらSIGCONTで目覚める. Torqueと違い,メモリーが溢れるならばおねんねしない(←なんでや?太すぎるやろ?)該当ジョブクラスでOverSubscribe=FORCEを指定しないと発動しない.
PreemptMode=GANG 下で説明するキャングスケジューリングが発動する.
PreemptMode=REQUEUE 高貴な方々の姿を見ると自殺(←あきらかに,やりすぎだろう?)するが, 高貴な方々が逝っちまったら,こそっと再投入される
PreemptMode=CANCEL 高貴な方々の姿を見ると自殺(←あきらかに,やりすぎだろう?)し,死んだまま
PreemptMode=CHECKPOINT 高貴な方々の姿を見るとなんらかの機能を使って自殺. Checkpointについては後述. 設定していないならばCANCELと同じになる
可能な組み合わせ:
| Partition設定 | 全体設定 | |||||
| SUSPEND | GANG | REQUEUE | CANCEL | CHECKPOINT | ||
|---|---|---|---|---|---|---|
| SUSPEND | OK | OK | ? | ? | ? | |
| GANG | OK | OK | ? | ? | ? | |
| REQUEUE | ? | ? | ? | ? | ? | |
| CANCEL | ? | ? | ? | ? | ? | |
| CHECKPOINT | ? | ? | ? | ? | ? | |
ギャングスケジューリング 優先度の高いジョブが入ってくると,優先度の低いジョブを定期的にサスペンドし,優先度の高いジョブを優先して実行するようにする.へえ・・・優先度が低い方が完全に止まるわけではない,名前に似合わぬ紳士的なポリシーだなのね.いいじゃないか,実現しよう.
GangSchedulingでは,メモリー溢れをすることは避けなければなりません.そうしなければメモリーがハードディスクに書き出されるswapが発生し,計算速度が著しく落ちます.メモリー溢れを防ぐため,以下の設定が必要です.
-
select/linear CR_Memory
- select/cons_res CR_Core_Memory CR_CPU_Meomry CR_socket_Memory
怠慢なユーザーは,自分の使用メモリーをジョブ文に書かないです.すると最大メモリーを割り当ててしまうため,メモリー制限に100%引っかかります. 怠慢でないユーザーは存在しないため,ギャングスケジューリングが有効になることは一度もありません.じゃけん,DefMemPerCPU か DefMemPerNode を宣言しておかないと,ほぼ意味はないです.
SchedulerTimeSlice デフォルトで30(秒). この時間間隔ごとにジョブを切り替えます.
OverSubscribe=FORCE:2 これが宣言してあるジョブクラスで, ギャングスケジューリングが有効になります. この例では, 2つのジョブまでが,TimeSliceによって実行されます.もちろん2以上も設定可能.
つあmりDefMemPerNodeをノードの半分くらいに設定しておけば,まあまあ,寝ることができる.よさそうな考えではあるが,怠慢なユーザーが最大メモリーを設定することは考えにくい.彼らは確実に次の文句を言ってくるだろう:
- この計算機,128GBメモリーなのに,俺のジョブがMEMORY OVERで止まった!死ねやコラ!そのクソ設定のせいだ!止めろやオラオラ!
困ったな.こんな奴に,メモリー使用量の設定をお前のジョブ文に書けよ解決するから,と説明しても
- 俺がどんな量のメモリーを使っているか?知るわけないやろタコ
となる未来が見えるな.この事態を防ぐには,ジョブが終了するたびに,使用メモリーレポートを出す必要があるなあ.
preemot/part_prio の具体的な例は,こげな感じばい:
#行の最初が#である場合のみ,コメント PreemptType=preempt/partition_prio PreemptMode=SUSPEND,GANG SchedulerTimeSlice=60 ←1分でタイムスライス DefMemPerCPU=1000 ←デフォルトで1GBメモリ確保(実質的にメモリー指定必須ですね) PartitionName=first OverSubscribe=FORCE:1 PriorityTier=5 PreemptMode=off PartitionName=business OverSubscribe=FORCE:1 PriorityTier=3 PreemptMode=suspend PartitionName=economy OverSubscribe=NO PriorityTier=1 PreemptMode=requeue
firstクラスは,他の誰にも邪魔されない.businessクラスは, firstクラスの人が来たらsuspend行動をとる. economyクラスは,businessクラスやfirstクラスの人を見ただけで目が潰れてジョブがキャンセルされ,高貴な人がいなくなったらジョブを打ち直す. Shared=FORCE:1 (Timeslice実行数が1)であるので,ギャングスケジューリングは発動しない.
いや・・・幾ら何でも,ジョブがキャンセルされる・・・っていうのは非人道的じゃないか?