はじめてのC++プログラム
XCodeやVisual Studio, Eclipseなどで次のプログラムを作成しましょう. (作成しなくても, XCodeでターゲットを作ると, 下記のものが初期に記入されてますが)
#include<iostream>
int main(int argc, const char * argv[]) {
// Insert your code here...
std::cout <<"Hello, World!\n";
};
コンピュータにおけるプログラム言語というのは,上記のような人間が読める文字列で指示を記入し,コンピュータがそれを判読して電子的に実行するものです.方法は大きく分けて2通り:
- 一行読むたびに,即座に実行する「スクリプト」型の言語(bash, JavaScript, Python, perl, Basicなど)
- 読み込んだ順に,プログラムが実行されます
- 実際には,数行読んでこっそりコンパイルし,安全確保するけどね
- 実行中にプログラムを書き換えることも可能.自分自身を書き換えることも可能
- 読み込んだ順に,プログラムが実行されます
- あらかじめ間違いがないかチェックしてコンピュータが理解できる形に変換(コンパイル)して「実行ファイル」に保存しておく.実行ファイルをクリックすると実行される(C++, C#, Java, perl, Basic, Fortran)
- コンパイルしなければならないので,実行中にプログラムを書き換えることは不可.その代わり,何度でも同じ結果を生む安定性を持つ.
- 多くの場合, 最初にmain() 関数を実行するという約束があります.
- プログラムに間違いがあると,一部はコンパイル時にエラーが表示されます.
- XCodeやVSを用いていると,コンパイルする前にエラーを出してくれます:

- XCodeやVSを用いていると,コンパイルする前にエラーを出してくれます:
- コンパイル時にエラーしなくても,実行時にエラーすることがあります.
- XCodeやVSを用いていると,実行時に,どこでどうしてエラーしたのか表示してもらえます:
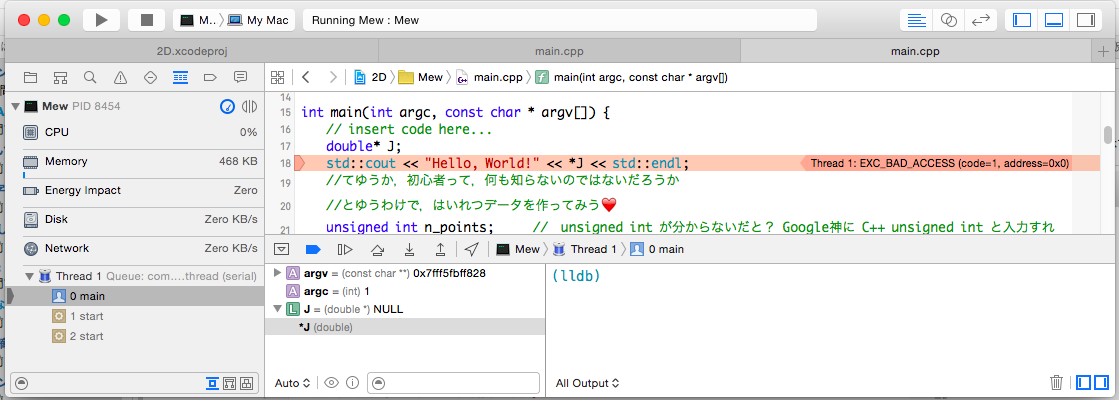
- XCodeやVSを用いていると,実行時に,どこでどうしてエラーしたのか表示してもらえます:
- いやもう何が何でもコマンドラインで行いたい変人は,ターミナルで
- clang++ -std=c++11 myprogram.cpp (OSX)
- icpc -std=c++11 myprogram.cpp (Linux-Intel)
- g++ myprogram.cpp (Linux-GCC ええっとCentOS6系列だと新規格C++11を理解しないかもしれないね. OSが古すぎて残念でした.苦海に沈んでね)
- Windowsでコマンドラインって基地外
XCodeなどでは,再生ボタンをクリックすると,コンパイルを行ったのち,実行が行われます. 上の例では, main()関数を実行しようとします. //で始まる行は「コメント」であって,プログラムの説明ですので読み飛ばされます.で,
std::cout <<"Hello, World!\n";
を行うわけですが, これは「画面に次の文字を書け」という命令です.というわけで,上のプログラムを再生すると"Hello, World!改行" が出力されて終了します.
歴史および将来
どのプログラミング言語も, 時代についれて変化していきます.時に巨大な変化が起こります.
- Fortran言語は, Fortran77が20-30年使われたのち, 2000年ごろに大幅に異なるFortran90に移行しました.
- C++言語は, C++98が15年ほど使われたのち,2014年ごろに大変更されたC++11に移行しました.2024年くらいまでは,大幅な変更はなさそう?です.
- C++98 Fortran竜やperlザウルスが跳梁闊歩し, 人類はまだ存在していなかった.
- C++03 暗黒時代. 全てのものを手で書く原始人の中で, Boost教団が光をもたらそうとしていた.
- C++11 黎明期.人間にもプログラムを書くことが可能になった
- C++14 普通の人がプログラムを書けるようになった. というかJavaScriptみたいになってきた
- C++20 すべてのプログラムは絶滅し, JavaScriptだけになるかもしれないね.
長大な期間使われた言語は, 図書やWeb情報が多いため,旧規格の情報を使ってしまう場合があります.C++の場合, 2015年以前の図書は利用参照しないほうが身のためです.
変数
プログラムの目的はさまざまですが,多くの場合,数値や文字列のデータを処理することが多いですね. プログラム言語では, それらのデータを「変数」というものに保存します.ほとんどの言語で,データの保存には次の形が用いられます.
xxx=1.235;
左辺の「xxx」が変数で,右辺の1.235はデータです. この一行で, 1.235という値のコピーがxxxに保存されます. 数式のように見えるかもしれませんが,数式ではありません.数式ならば
1.235=xxx;
でも正しいはずですが,これは動作しません.はっきり言えば, プログラミングの = は数学の等号ではありません.=は「値のコピーを作成し変数にセットする」命令です.ですので
xxx=yyy;
ではyyyの値のコピーをxxxに保存されます.あなたが今から使うコンピュータは知性を持ちませんので,「代入」の概念を理解しません.必ず「コピー」を作成します.代入とコピーの違い(コピーの場合にはオリジナルが残る.代入ではオリジナルの存在意義が消失する)は,将来オブジェクト変数を扱う場合に重要ですので,違いを理解しておく必要があります.
右辺のyyyの値を「右辺値」,左辺のxxxを「左辺値」と呼ぶことがあります.
変数を使う場合に,プログラム言語によっては制限があります:
- 流儀その1:変数を使う前に,それが浮動小数点数(1.235とか)を保存するのか, 整数(24とか)なのか,文字列("Hello, World"とか)なのかを「宣言」しなければならない
- C++, Fortranなど.
- CやFortranなどコンピュータの能力がほぼ0だった頃の古典言語では,宣言をプログラムの最初の方に書かなければならない縛りがあったりします.変数の定義が数百行も前に書いてあったりして,バグの温床となる謎仕様でした.
- 流儀その2:値を見たらどんな変数か想像できるので,「宣言」は基本的に不要
- Javascript, Basicなど
- If it walks like a duck and quacks like a duck, it must be a duck というのが基準だそうで,ダック型と呼ぶそうです.
C++では,宣言は次のように行います:
double x_max=1.235;
int n_points=128;
std::string my_name="Hiroshi Sugimoto";
doubleってのが浮動小数点(精度の低い floatもありますけど), intってのが整数, std::string ってのが文字列です. 変数といってもコンピュータに記録するわけですから,数値の範囲には制限があります. 特に整数では問題になることがあるので, short, long, long long...など,別名の整数で,多くの桁数が保存できます. 何桁いけるかは実装依存ですが, 多いケースは
- short 16ビットつまり 2^16=65536パターン保存できるので, -32768 ~ 32767 あるいは 0 ~ 65535 (unsigned short)
- 10年くらい前は, これをlongと呼んでましたわ^o^ shortの最大値は256くらいだったと思う
- long (int) 32ビットで-2147483648 ~ 2147483647 あるいは 0 ~ 4294967295 (unsigned long)
- long long 64ビットで-9223372036854775808 ~ 9223372036854775807
文字列の名前が std:: とかついて奇妙ですね.画面への出力も std::cout とか書いてました.これらは,言語規格を拡張した「標準ライブラリー」を意味しています.C++では「文字列」の規定は無く,「文字」char型があるのですが,文字というものは1文字だけで使うことは無いので,charを利用するのは極めて困難です.charを使うのは古代人およびシステム・プログラマーに任せて,我々は文字列の結合とか分解とかが装備済みの std::string を使いましょう.「Standard Library」を除くと,多くのC++要素は古代人向けのもので難解です.STLはプロ&Intelが高速にプログラムを実行できるように工夫した成果なので,車輪の再発明(STLを避けて低速なプログラムを書く)は止めて,STLを利用するようにしましょう.間違ってもSTLがどう書いてあるのか理解しようとしてはなりません.
計算式
変数を使って,計算を行うことが可能です. かけ算は* (xや.ではアリマセン!), 割り算は/ (÷ではない!),足し算は+, 引き算は-です. 括弧()を用いて,演算の優先順位を明確にできます. 例えば
x_av=(x_max+x_min)/2;
こんな感じです. この他に,C++には変態チックな演算子があって,
C++; // 変数Cの値を1増やす
C--; // 変数Cの値を1減らす
C*=3; // 変数Cに3を掛ける
C/=2; // 変数Cを2で割る
条件に応じた演算を書くことも可能です.例えば i>0 の場合だけ計算したい場合
if (i>0) x_av=(x_max+x_min)/2;
ですね.i>0でない場合に別の計算を行う場合:
if (i>0) x_av=(x_max+x_min)/2;
else x_av=(x_max-x_min)/2;
- x && y xかつy (AND)
- x || y xあるいはy (OR)
- !x xではない
- x > y xがyより大なら true
- x >= y xがy以上なら true
- x == y xとyが等しければ true
- x != y xとyが異なれば true
if (i>0) {//文法的には if {} だけで1命令
x_av=(x_max+x_min)/2;
std::cout << "Normal average:" << x_av << std::endl; // std::endl は改行
}
else { //文法的には else {} で直前の if {} が該当しない場合に該当するという1つのコマンド
x_av=(x_max-x_min)/2;
std::cout << "Abnormal average:" << x_av << std::endl;
}
指数関数や三角関数などの数学関数を使う場合には, プログラムの最初の方に
#include <cmath>
を記入すれば利用可能になります. 指数関数は std::exp, 平方根 std::sqrt, 三角関数 std::sin等, 冪x^nは std::pow(x,n), 誤差関数は std::erfです.
例: double Y=std::exp(1.23);
浮動小数点 1.234 などから整数値を計算することは,意外に多いので,様々なバリエーションが用意されています:
- std::floor(x) x以下で最大の整数. std::floor(-1.3)=-2 std::floor(1.3)=1 std::floor(-3)=-3
- std::ceil(x) x以上の最小の整数. std::ceil(-1.3)=-1 std::ceil(1.3)=2 std::ceil(-3)=-3
- std::round(x) xを四捨五入整数
- std::trunc(x) xの小数点以下を斬捨 std::trunc(-1.3)=-1 std::trunc(1.3)=1 std::trunc(-3)=-3
数字と文字列の変換もよく用います.
- 数字→文字列 your_string_variable = std::to_string(数値変数);
- 文字列→数字 std::stringstream(文字列) >> your_numeric_variable; このstd::stringstream は・・・あとでファイルの入出力で学ぶ
- long INTEGER = std::stol(文字列); longのとき. double用のstd::stod, float用のstd::stofとか unsigned long long用の std::stoullとか,名前がダサい関数もある. どうして std::to_long() とか std::to_double() とかにしなかったんだろう・・・?
整数を2進法で書くと, 例えば 22 = 0b10110 であり, 0と1の羅列になる. これをスイッチとして利用するけち臭いプログラムもある.この場合, bit同士のANDとかORとかNOTの演算がある.
- x & y xとyのBIT-AND
- x | y xとyのBIT-OR
- ~ x NOT x
条件判断
if文以外に, 条件分岐にもう一つswitch文があります. 他のプログラム言語では無類に強力なswtich文ですが, C++のは極めて貧相で, 整数値によって分類できるだけです:
switch (整数値) {
case 1: 値が1の場合のブロック.もちろん1以外の数字でもOK
....
break;
case 2: 値が2の場合のブロック
....
break;
default:どこにも該当しない場合のブロック
....
break;
}
整数値によって実行される文を分けられます. break文があると, switch{}を抜けます. breakがない場合,次のブロックを続けて実行します.どのcaseにも該当しない場合, defaultブロックを実行します.
C++のswitch()[}は, 実は以下のコードと同じです:
if (整数値==1) goto case_1:;
if (整数値==2) goto case_2:;
goto default::
case_1: 値が1のブロック; goto end:; // break文は最後のgotoに対応する
case_2: 値が1のブロック; goto end:;
...
default: デフォルトブロック;
end:; // 文字列: というのは,C++の「文ラベル」である
ですので, ブロックの内部に変数宣言があると, 外側や別ラベルのブロックに影響が出ます. ブロックを{ } で囲んでおけば, 当然ながら影響をなくすことができます.
配列
同様の多数のデータを使う方法の一つは,配列を使うことである. C++の配列は
std::vector<double> Y;
int N=100;
Y.resize(N);
で作成する.<>内の型を持つ複数のデータがYである. 幾つのデータを用いるかを resize命令で指示している. この「ポツ」.の意味は後に明らかになる. resize(100)によって, 0-99の100個のデータが利用可能になる:
Y[22]=22.323;
などと[]を付けて用いる. ただし, Y[102]などと範囲外をアクセスすると,実行時に計算を間違えた上,間違いに気付かずに計算を続行する.いや間違えるのではなく,「範囲外ですよ」とエラーが起こってほしい場合には
Y.at(22)=22.323;
と書けば良い.アクセスするたびに,番号が範囲内であるかいちいち条件判断し,低速だが安全な計算を行う.高速で安全な計算がほしいだと?無理を言うな.どっちか選べ.配列の個数は
int M=Y.size();
で取得できる. 配列の個数が不足している場合,
Y.push(53.322);
で, 末尾に新しく53.322を追加できる.いやいっぺんにガーッと増やしたい場合,
Y.resize(1000);
で1000個まで増える. pushと同じ程度の計算時間で, 一発で多数のデータを確保できる(よーするにreserve()していないpush()が低速である). 古い範囲のデータは可能なら保持される. resize()で要素数を減らすことも可能であるし, Y.clear() で全部削除することもできる.
ループ
配列を用いると,繰り返し計算を行う必要が出てくる. これには for文, while文, do文などを用いる.
数えるfor文
あまり簡単ではないが,数えながら繰り返す方法である.for(開始条件;終了条件;次の準備){...} と書けば, 最初に開始条件を実行,終了条件を満たさなければ{...}を実行.次の準備を行って終了条件を満たさなければ{...}を実行,を繰り返す. 例えば
for(int i=1;i<10;i++) {
std::cout << i << " ";
}
std::cout << std::endl;
では, 「1 2 3 4 5 6 7 8 9 改行」が出力される.
全部のfor文
繰り返す場合には配列を用いるわけであるから,配列の全てにこれを行え,と書くことができる. 配列 YXY の要素全てに何かを行う場合
for(auto &NyanNyan: YXY){
ここでは NyanNyan がYXYの各要素であるので,それを使って式を書く
}
と書ける. NyanNyanの前のautoは,「型推論」と言って,適当な変数を準備してくれる有難い命令である(書き忘れたらautoになる,と定めてくれた方がJavaScript並みで有難いと思うのだが...).autoの後ろの&は後に説明する「参照」である.今は黙って書いておけば良い. XYXがstd::vectorである場合, 最初から初めて,最後の要素まで順番に実行される.
変数 my_variable と同じ型の変数をもう一個作りたいとき, auto(my_variable) your_variable と書きたいところだが,これはなぜか
decltype(my_variable) your_variable;
と書かなければならない. なんでだろう? そう思っていたら,こう書いたら良いらしい
auto your_variable=my_variable;
初期値が与えられちまうけどな
全部のfor文2
配列の全てで繰り返す場合,もっと原始的な表記も可能である.
for(auto it = YXY.begin(); it != YXY.end(); it++){
ここでは *it がYXYの要素である.*は後に説明する「ポインタ」である.まあ黙って*と書け
}
この it のように,配列の各要素を順番にスキャンする変数を「イテレータ」という. it を auto で宣言しているが,auto と書きたくないマジきちは, std::vector<double>::iterator と書いても良い.2014年ごろまでは,みんなそう書いていた.別のパターンとして,逆順に実行する書き方もある.
for(auto it = YXY.rbegin(); it != YXY.rend(); it++){// この場合 it は std::vector<double>::reverse_iteratorになる・・・もう知らなくて良いけど
....
}
Q: さっきは auto & だったのに, イテレータでは auto なんですね?
A: まあ auto & で良い. ただまあ, auto & が auto よりも計算が高速なのだが, イテレータの場合には速度に違いはないので, & を省けばプログラムが1文字短くできる. それが馬鹿馬鹿しい場合には, もう黙って auto & と書けば良い
while文
ある条件が満たされるまで繰り返す,という書き方である.
auto it=YXY.begin();
while (条件){
....作業....
if (....) break; // 途中で抜けたくなったら break; で脱出可能. 普通のfor(;;)でも可能
....作業....
if (....) {
it++; // 途中で,もう次のをやりたくなったら continue
continue;
}
....作業....
it++; // 忘れずにitを前に進めないと無限ループするよ
}
上の例ではiteratorを用いたが, もちろん,ただの整数 i とYXY.size()を使って書くことも可能である.
do文
while文で条件が最後にくるパターンである.
int i=0;
do {
.....
YXY[i]=.....
...
i++;
} while (i<YXY.size())
クラス
数値計算では,複数の数値がひとまとまりになることが多くあります.例えば,流体中のある微小領域--セル--における質量,運動量,エネルギーあるいは流速や圧力,温度は1セットになっている方がわかりやすいわけです.これには「クラス」を用います.
class Cell {
publuc: //publicと言っておかないと, 外部から見えない変数ができてしまう
double X;
double Y;
}
ここでは, XとYのペアでクラスを作成しました. これを使うには
Cell MY_CELL;
これで, MY_CELLを次のように利用できます.
MY_CELL.X=10;
std::cout << "Value of X=" << MY_CELL.X << std::endl;
上の例で分かるように, クラスの要素は .X とか .Y でアクセス可能です. クラスの配列は
std::vector<Cell> cells;
cells.resize(N);
for(int i=0;i<cells.size();i++) cells[i].X=dx*i;
ですねー.
さて,プログラムを作成する場合,データには自然な「まとまり」があります.例えば,上のCellが多数集まると,流体領域ができそうです.様々なパラメータは,Cellに属するもの, 領域に固有なもの・・・に分類できそうです.分類を間違えてもプログラムは書けるわけですが,不自然な(センスのない)分類をすると,プログラムが煩雑で下手くそに見えます.
では早速Cellを集めてRegionを作成しましょう.
class Region{
public:
std::vector<Cell> cells;
double T_w; //領域に固有なパラメータは,こんな風にRegionで定義すると良い
}
Cellを操作するプログラムを, Region につけることが可能です. 例えば, Cellの数を与える Init()関数をつけてみましょう.
class Region{
public:
std::vector<Cell> cells;
double T_w;
int Init(unsigned int N){ // これが関数の定義. unsigned int の数Nを受け取り,何か整数を返す関数である
cells.resize(N);
return 1; // 上で関数を返すと言ったので,何か整数を返さないとエラーになる
}
void Altanative(unsigned int N){ // いや,返す数なんてねえよ,という場合は void と宣言する
cells.resize(N);
}
}
呼びだすときには
Region My_Region; //Regionクラスの変数(オブジェクト)を1つ作成
My_Region.Init(20); //My_Regionにセルを20個作成
これは, cells.resize(N)と同じような感じですね・・・実は std::vector はクラスなんですよ.<double> ってのの<....>はテンプレートとよび,後に学びます. std:: の::は名前空間と言って,これも後で学びます.
しかしまあ,なんですな,Regionを作ってInit()を呼び出さない,ってパターンはありませんね. そこで,初期化の時は,これをやる,という特殊な関数があります.コンストラクタと呼び,次のように定義します:
class Region{
public:
std::vector<Cell> cells;
double T_w;
Region(unsigned int N){ // コンストラクタは必ず void 型であり, その名前はクラス名と一致する
cells.resize(N);
}
~Region(){ //~クラス名, というのはデストラクタとよび,変数が消える直前に実行される.
cells.clear(); // 変数が消えるとは,例えばプログラムの終了時,などである
}
void set_BC(double Y_w){
cells[0].Y=Y_w;
}
}
この場合には, Regionの作成時に
Region My_Region(20);
と作成します.
オブジェクトの配列
上の例では,Cellクラスの変数の配列 cells を作成しています. ですが, クラスには関数も含まれているわけで,「変数」と呼ぶのは正確さに欠けています.そこで,クラスで宣言した「変数と関数のセット」を「オブジェクト」と呼びます.Cellオブジェクトの配列は,上に述べた通り
std::vector<Cell> cells;
でよいのですが, では, ある数値シミュレーションに多数の領域 Region がある場合は,どうするのでしょうか?
std::vector<Region> regions;
で領域配列は作れますが, 領域の数を28に設定しようとして
regions.resize(28);
ではエラーが起こります.Regionクラスのコンストラクタに与える引数 N が不明だからです. この場合には, resize()ではなくemplace()を用います.
for(int i=0;i<28;i++) regions.emplace_back(N); //まあemplaceの引数に, コンストラクタに与える引数たちを入れるわけよ
ただし, 上のプログラムには,まだまだ問題があります.std::vectorは,サイズが増やせる配列ですが,実際には次の挙動を取ります:
- 要素数が不足した
- では,全く新規に,現在の要素数 size()+1 のデータ領域を作成
- 現在の要素を,新しいデータ領域にコピー
- 古いデータ領域を削除
ということは・・・上のfor分では, 28回も,データを作ったり消したりを繰り返すわけです(Regionのデストラクタやコンストラクタでメッセージを表示させてみれば分かります).これは時間の無駄です.必要な要素数は分かっているのですから,要素数を予約--英語でreserve--する必要が有ります.そこで, std::vector には,ちゃーんと reserve() 命令があります. これは,実際の要素数ではなく,「ここまでは要素数が増やせますよ」という数を設定します.次のように書けば良いのです
regions.reserve(40); // いや別に28個予約すればいいんですけどね. まあいいじゃねえか
for(int i=0;i<28;i++) regions.emplace_back(N);
なお,emplaceの他に, push_back とか insert とか色々有りますが, いずれも「引数のオブジェクトのコピーを作成し,そのコピーを追加する」という機能です.emplace()だけは異なり,「(もし与えられていれば)emplaceの引数を使って作成した,新しいオブジェクトを追加する」機能を持っています.引数のコピーを保持するのではない点が,pushやinsertとは違います.
もちろん, emplace()で作成したオブジェクトも, vector の要素数が不足してコピーが発生したら,やはりコピーになってしまいます.
コピーか,本物か,の違いは,後に説明する「ポインター」を利用する場合に重要です.例えば
Region *main_region = regions[0];
これで main_region で0番領域にアクセスできると信じていたとしましょう.しかし, ある時点で regions の要素数が不足してコピーが発生したら・・・regions[0]のデータの方向は,コピー前とは異なった方向になります.コピーが発生した後に main_region にアクセスを試みると・・・運が良ければ「segmentation fault」エラーが起こります.運が悪ければ,プログラムは誤った結果を生み出しつつ,正常終了します.
と.いうわけで,「絶対にコピーを発生して欲しくない」配列が必要なケースはあります.これは,配列となるクラスで,コピーが発生するとエラーするように仕込めばOK.これは,クラスのコピーコンストラクタを自分で与えることで実現できます.コピーコンストラクタの書き方は・・・Googleで
std::vectorにemplace()したオブジェクトは, vectorがclear()されたり, 消えたりするときにデストラクタが呼び出されて終了します.
もう気がついていると思いますが,このページを読んでも,自分でプログラムを試しに組まなければ,理解は不可能です.適当なサンプルを元にいろいろ遊ばなければ,理解は不可能です.書いてあることが本当に生じるのか,検証しながら読まなければなりません.どうやったら検証できるのかは,理解していれば考えることができるはず,です.(お遊びプログラム例:弾倉交換システムを作ってみる )
前方宣言とプロトタイプ
public:
std::vector<Cell> cells;
double T_w;
Region(unsigned int N);
~Region();
void set_BC(double Y_w);
void set_BC(double Y_w,int i);
}
Region::Region(unsigned int N){
cells.resize(N);
}
Region::~Region(){
cells.clear();
}
void Region::set_BC(double Y_w){
cells[0].Y=Y_w;
}
void Region::set_BC(double Y_w, int i){
cells[i].Y=Y_w;
}
class Region{
public:
std::vector<Cell> cells;
double T_w;
Region(unsigned int N);
~Region();
void set_BC(double Y_w);
void set_BC(double Y_w,int i);
}
- #define 変数名 変数を定義する
- #define 変数名 値 値を持った変数を定義する
- #define 関数名(変数名) 関数の値式
- #ifdef 変数名 ifndef というのもあって,それは逆になる
.... 変数が定義されていれば, ここをコンパイル
#else
.... 変数が定義されていなければ,ここをコンパイル
#endif - #include <ファイル名> C++標準のライブラリーの定義を読み込む
- #include "ファイル名" お前らの.hppファイルを読み込む
これを用いると,多数回読み込まれてもOKなヘッダーファイルを作成できる:
#ifndef region_t 1回目の読み込みでは region_t は未定義
#define region_t 1回目の読み込みではここに到達し, region_t が定義される
#include "cell.hpp" 1回目の読み込みではここいらを定義していく...
class Region{
public:
std::vector<Cell> cells;
double T_w;
Region(unsigned int N);
~Region();
void set_BC(double Y_w);
}
#else 2回目の読み込みでは region_t が定義済みなので,ここに到達.
#endif 2回目の読み込みでは,何も定義しないまま終了.この場合#elseは不要だな
XCodeでは,【File】【New】【Header File】を行うと,黙って上記の#ifndef...#endif構造が作成される.
C++では,このようにクラスの定義を別ファイルに書くのが正常である.結果として, 1セットの.hpp, .cppファイルで 1クラスを書くのが普通であり,一つのファイルに複数のクラスを定義するのは,禁忌である.
さて, 1クラス1ファイルとして作成すると,相互に参照するクラスを書けなくなる. このような場合には, 前方宣言を定義する.
----- FILE: CL_A.hpp ----
class CL_B; // 前方宣言. とにかく CL_B がクラスである,ことを調教
class CL_A {
public:
CL_B* cb; // これだけなら, CL_Bがクラスである,以外の情報は必要無い
......
}
---- FILE: CL_B.hpp ----
class CL_A; // ここで #include "CL_A.hpp" とすると, CL_A.hppがCL_B.hppに依存しているのか,
// CL_B.hpp が CL_A.hpp に依存しているのか, 不明瞭になる. ビルドシステムによってはエラーする
class CL_B {
public:
CL_A* ca; // 前方宣言 CL_A が無いと, CL_A が何か不明になってしまう.
....
}
この場合, cb や ca を実際に使う .cpp ファイルでは, その内容が必要になるので
---- FILE: CL_A.cpp ----
#include "CL_A.hpp"
#include "CL_B.hpp"
CL_A::method(...){
.....
cb->X=..... // CL_Bをincludeしているので,cbの内容はわかる
};
これで矛盾なく書くことができる.
実はヘッダーファイルに実装を書いても問題はない.つまりヘッダーファイルは次のようになる:
#ifndef region_t 1回目の読み込みでは region_t は未定義
#define region_t 1回目の読み込みではここに到達し, region_t が定義される
#include "cell.hpp" 1回目の読み込みではここいらを定義していく...
class Region{
public:
std::vector<Cell> cells;
double T_w;
Region(unsigned int N){
ここにプログラムを書いてしまっても,何の問題もない
};
~Region(){
ここにプログラムを書いてしまっても,何の問題もない
};
void set_BC(double Y_w){
ここにプログラムを書いてしまっても,何の問題もない
};
}
#endif 2回目の読み込みでは,何も定義しないまま終了.この場合#elseは不要だな
となると,
- 定義はヘッダーファイルに書いてある
- 本文もヘッダーファイルに書いてある
この場合,
- 本文.cppファイルが空っぽなので,気持ち的に寂しい.
- スーパー超巨大プログラムになると,ビルドするのが少々大変になる
- あなたのプログラムを販売する場合,ソースコードが丸見えになってしまうので,商売上困る
という問題が生じる.ビルドするのが大変といっても,最近のコンピュータは高速なので,まさに気持ちの問題だけである.あなたのソフトを販売することはないだろう. すると, 「あなたが作る程度のプログラムでは,.cppファイルには
#include "ヘッダーファイル.hpp"
だけが書いてあり,空っぽなのが学生の本分である」となる.まあ, 回避できない問題があって.cppファイルにプログラムを書く場合も, ないわけではない. プログラムが下手くそだと, 1クラスで数百行もある肥満化した醜い豚クラスを書いてしまうが,その場合,単に定義を見やすくするためにhppとcppを分けることもあるかな.
ポインター
微係数の計算を考えよう. 二つのセル A_CELL と B_CELL で計算できる微係数は
(A_CELL.Y - B_CELL.Y)/(A_CELL.X - B_CELL.X)
である. が,まあ普通は隣り合うセルで計算するわけだ. だから, 隣がすぐにわかると便利である. つまり「自分」から「あのデータ」とか,「このデータ」を指し示すことができれば便利である. そこで,次の構造を考える:
class BadCell{
public:
BadCell LEFT;
BadCell RIGHT;
}
あらかじめ
cell[i].LEFT=cell[i-1]; //cell[i]の左にあるのは cell[i-1]だよ〜ん
と教えておけば, LEFTやRIGHTで隣がわかるというアイデアである.しかし,これは問題がある.つまり,LEFT 等は cell[i-1] と同じ値を持つ「コピー」であることである. コピーと本物は,別の物体である.従って,コピーを取った後に本物を書き換えた場合,コピーには反映されない:
cell[i-1].Y=100;
cell[i].LEFT=cell[i-1]; // cell[i].LEFT は 100の値をもつセルの「コピー」
cell[i-1].Y=0.0;
上のコードでは, cell[i].LEFT.Y の値は, 変更後の0.0ではなく,コピーしたときの値 100 になる. 本来, LEFTは,コピーを保持するのではなく,「本物はあれ」と言いたいのである.このための変数が
「指差し屋」
である. 正式には「ポインタ」と呼ぶ.あるデータ型を指差したいときには, 変数名に*をつければ良い. つまり
class Cell{
public:
Cell *L; //人によっては Cell* L; と書く. もちろん Cell*L; と書いてもいいけど分かりにくいわー
Cell *R; //Cell* が「Cellを指差す」型だと思えば良い
double Y;
double dX;
}
と書く. (実際には,この形しか使われないので, 上の例で*を書き忘れるとエラーするんだけどね) さて,ポインタに値を代入するには
cell[i].L=cell[i-1];
ではダメである. 右辺の cell[i-1] は「データ」であって.左辺の「データのある方向」Lには代入できない.次のように書く.
cell[i].L= &cell[i-1];
ある変数に & をつけると,「データ」が「データのある方向」に変換されるわけよ. もちろん逆もある. ある変数に * をつけると,「データのある方向」が「データ」に変換される.例えば *L と書けば, それはCell型を持つデータになるのである. (だから宣言文では Cell *L と書いた)
というわけで,値を使うときには
double Y_value = *(cell[i].L).Y;
と書く. だが,これでは面倒なので略記法がある.
*Expression_can_be_compleX.Y は, Expression_can_be_compleX->Yと書く.
これを使うと
double Y_value = cell[i].L->Y;
cell[i].L->Y = 2*Y_value;
これでY_valueは自分の左隣のセルの現在のYの値になり, その2倍の値で更新する,ということになる.では, Cellが左右を知っているようにRegionを書き換えてみよう.
Region::Region(int _N,double _min=0.0,double _max=1.0){
std::cout << "CH: 点数は " << _N << ", 範囲は " << _min << ":" << _max << "みたいですな" << std::endl;
X_min=_min;
X_max=_max;
cells.resize(_N);
double dx=(X_max-X_min)/cells.size();
for(auto i=0;i<cells.size();i++) {// セル数を調教
cells[i].dX=dx;
if (i>0) cells[i].L=&cells[i-1]; else cells[i].L=NULL;
if (i+1<cells.size()) cells[i].R=&cells[i+1]; else cells[i].R=NULL;
};
};
上のコンストラクターでは, 各セルに左右を定義している. ただし, i=0 ではLに, iが最大では Rに代入するべき値がない. そういう値にうっかり cell[i].L->Y なんてアクセスをかけると, 実行時に「Segmentation Fault」などというエラーが発生する. そこで, 上の例では, 「指すべきものが無いんですけど」という記号 NULL を代入している.
なお, コンストラクターの引数で _min=0.0 と値をしれっと代入しているように見える.これは,省略時の値を与えているのである.つまり
Region HOT_Region(100,-3.0,0.0); // X_min=-3, X_max=0 で作成
Region COL_Region(200); // X_min=0, X_max=1で作成
さあこれで,Cellは隣のデータにアクセスできるようになった. 例えば次のメソッドをCellおよびRegionに追加すれば, 差分式
(右の.Y - 僕の.Y)/(右の.X - 僕の.X) = - 僕の.Y
を使って微分方程式を解くことができる. なお, 「僕の.Y」は, プログラム中では this->X と書いても良いが,まあ単に Yと書けばOK.
Cell::Update(){
R->Y = Y*(1-dx);
};
Region::Solve(){
for(auto C=cells.begin();C!=cells.end;C++) C->Update();
}
ううん・・・でも,これでは一番右端で
NULL->Y = Y*(1-dx);
になってしまって具合が悪いなあ. この対策は2通り
- Cell::Update()で, if 文でチェック
if (R!=NULL) R->Y=Y*(1-dx);
だが,これは計算速度に莫大な悪影響がある.例えば,1回の計算が100psかかり, if文が1ps時間を使うなら,セル数が10^6の場合, 無駄な計算時間が(10^6-1)*1ps ~ 1us増加する. - Regionにダミーデータを付け, コンストラクタでstencilを仕込んでおく.つまり
class Region {
private:
Cell BOKE;
....
}
Region::Region(...){
.....
if (i+1<cells.size()) cells[i].R=&cells[i+1]; else cells[i].R=&BOKE;
この場合, 右端のセルでは無駄な計算を行い, 結果をBOKEに代入する. 無駄な計算時間は100psである. まあようするに,回数が多いループに,if 文なんか入れるなボケ,と言いたいわけです.ほんのわずかでも入ると,計算速度は劇的に低下します. - いやまあ,普通に,ループの回る回数を工夫する.
auto C=cells.begin();for(C++;C!=cells.end();C++) C->Update();
あれ?これではUpdate()も書き換えとかないと
Cell::Update(){
Y=(Y->L)*(1-dx);
}
cells.end()の一つ前を,事前に計算しておくという手もある:
class Region {
private:
Cell *BOKE;
......
}
Region::Region(...){
......
if (i+1<cells.size()) cells[i].R=&cells[i+1]; else BOKE=&cells[i];
ほんでループを
for(auto C=cells.begin();&(*C)!=BOKE;C++) C->Update();
// &*C って C ではないのか,と思うかもしれませんが, 上のCはイテレータであり,その * は通常の*とは定義が違います
// C++でイテレータが先に進む,ってのも, 値を1加えているわけではない.イテレータは特殊な変数です.
空間1次元の解析では自分の左右がわかれば十分ですが, 多次元の計算になると上下前後も必要になります.これも同様に設定すれば可能です.ただし,std::vectorが元来空間1次元であるので, それをどのように並べるかは重要です. まあ普通は

こういう風に配置して使います.まあでも, Aセルが必要なデータは空色部分ですから,必要なデータが随分離れたところにあるわけですね.例えば蕎麦屋に行ってざるそばがこんな風に皿に乗っていたら,食べにくくて仕方がありません.蕎麦がぷつぷつ切れてしまいます.コンピュータでも,遠く離れたデータは低速なメインメモリーボードからお取り寄せになるので,計算速度は劇的に低下します.でも,1列づつ別のCPUで並列計算する,といった積極的な理由があるならともかく,1次元に並べる必然性は元来ありません.蕎麦も,まともな蕎麦屋は次の形で皿に載せます.
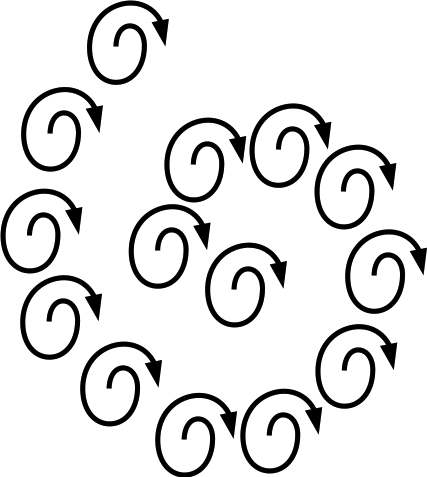
まあこの形は実現できない?わけですが,できるだけこの形に近づくことができれば,メインメモリーよりも10倍程度高速なキャッシュメモリー上で計算を行うことが可能になります. まあ, 本来大きなデータを, キャッシュサイズ以下の領域に分割し,境目をポインターで同期・・・といった小技は,特定の分野では普通なんだそうです.
参照
ポインタの別の利用方法を解説しよう. 次のような関数を考える.
Region::set_BC(double Yw,double *dYw){
cells[0].Y=Yw;
Yw=0.0;
*dYw=0.0:
}
set_BC()は, Ywの値を受け取り, 使用した後, 0に変更している. ところが,これを次のように実行してみると, Yw=0.0 になっていないのである.
double yw=300; double dyw=2.0;
HOT_Region.set_BC(yw, &dyw);
std::cout << yw << std::endl; // 300のままになっている!
std::cout << dyw << std::endl; // dywは0に変更されている
これは, C++では, メソッドの引数は「コピー」を作成して送る,というルールがあるからである. set_BC()で YW=0.0 としても,コピーの値が変更されているので, 呼び出し側では値が変わっていない. set_BC()で変更した値を呼び出し側で利用したい場合には,メソッドの引数に「指差し」を与えれば良い. 上のdYwがその例である. コピーされるのは &dyw つまり 「dywの方向」であり, set_BC()では,「 dywの方向」にあるデータに0を代入するので,呼び出し側の値がちゃんと変更される.
ただし, このようなポインターの利用は,古来よりバグの温床となってきた.つまり
- &dYWの場所に,攻撃対象の方向(実際にはコンピュータのメモリーのアドレス)を指定し,誤動作によってセキュリティーを破る
- 数値計算プログラムでは,&dYWの場所にバグがあっても,ソフトウェアは見当違いな場所の数値を上書きし,しかも,エラーが発生しない(正常終了しているように見えるが,結果は大間違い)
現在では,可能な限りポインターは使わないのが常識である.(C#のように新しい言語ではポインターは廃止されている.C#でWindowsが書けているのだから, ポインターが無くても何でも書けることは証明済みである.) ポインターの代わりに用いられるのが「参照」である.この参照は,どこかで定義した左辺値に対する参照なので,正確には「左辺値参照」という.参照を使った set_BC()は次のようになる:
Region::set_BC(double &Yw,double &dYw){
cells[0].Y=Yw;
Yw=0.0;
dYw=0.0:
}
double yw=300; double dyw=2.0;
HOT_Region.set_BC(yw, dyw);
呼び出す時には, 普通の変数を渡している. しかし,受け取り側の関数の引数が&dYWとなっている.この場合,関数のdYWは本体のdywの参照ーつまり同じものになる. そのため,関数中でdYWを変更すると本体のdywの値が変更される.このように,参照はポインターに似ているが,「いつも,現有の何かを指し示している」というところが異なる.「現有の」ってところがポイントで,自分が持っていない値を参照することはできず,見当違いな参照を作り出すのは比較的困難である.また,参照はNULLになることもない.
最後に, クラスの変数に左辺値参照を使う方法を学ぼう.
class NEWCL{
public:
double &Ref_VAL; //Ref_VALは参照として定義している. NEWCLクラスを初期化するときには, その先が定まってなければならない
//
//仕方がないので, Ref_VALの初期化はコンストラクタで行う.すなわち
//1: コンストラクタの引数で必要な数を受け取る. 下の例ではYYYを受け取っている.
//2: 初期化リストを使って参照を初期化する. 下の例では, Ref_VALはYYYデータを指し示す参照として初期化される.
//
NEWCL(double &YYY):Ref_VAL(YYY){....};
}//クラス変数に参照が含まれている場合, コンストラクタの初期化リストで初期化しなければ, エラーが出てコンパイルできない
変数のスコープ
クラスにおける関数や変数を定める場合, ある程度の変数は, クラス外部から参照される可能性が無かったり, クラス外部から操作されるのと具合が悪い場合がある. それらはクラスの private な変数・関数であると定義すればよい. すなわち, ヘッダーで次のように定義する
class Region {
private:
int _nPoints;
double _err_threthold;
double _process_Once(double X_w,double Y_w);
public:
....
}
この例では, _nPoints, _err_threthold, 関数 _process_Once() は, クラス内部の関数だけからアクセスが可能になる. つまり,
Region R(100);
R._nPoints=100;
と書くことができなくなる. このように変数や関数を隠すことで,他人でも安全に利用できるプログラムを作成することができる.
なお, private変数がアクセスを禁止しているのは,あくまでも,「別のクラス」である.実体(インスタンス)が異なっても,クラスが同じであればprivate変数にはアクセスできる.
class Region{
private:
std::string name;
public:
Region(std::string _name):name(_name){};
void print_name(Region *R){ std::cout << R->name << std::endl;}
.....
Region A("hoge");
Region B("Boke");B.print_name(&A); //<--- Bの関数であるが, Aのprivateなnameを利用可能
これとは逆に, クラスの全オブジェクトで共通な値を使いたい場合もある. つまり
Region HOT(20);
Region COLD(30);
のように, HOTなRegionとCOLDなRegionがあった場合に, HOTとCOLDで共通の値を用いるというケースである. このような変数は static な変数と呼び,
class Region{
private:
.....
public:
....
static unsigned int N_COUNT;
const unsigned int CONSTANT=20;
....
}
という風に, staticで修飾する. 変数のスコープでは無いが, const修飾というものもあり,これは値を変更できない定数を意味する.
変数の有効範囲を限定したいことはよくある. 例えば整数を i, j,...と名付けることは一般的であるが, 一般的であるので
....
int i=20;
....
while (i>0) {....}
....
int i=30;
と書くと, 2回目の int i 宣言でエラーしてしまう. このような場合には, {}で変数の範囲を限定すればよい:
.....
{
int i=20;
....
while(i>0) {....}
.....
}
{
int i=30;
変数 i の有効範囲「スコープ」は{}内部に限られるので, 2回目も, 単純な変数名 i を用いることができる.
ファイル入出力
データをファイルから読み取ったり,書き出したりする必要があるでしょう.これはstd::ofstreamやstd::ifstreamクラスを利用します. まずファイル名を作りましょう.
std::string my_home=getenv("HOME"); //文字列 my_home にホームフォルダのパス(/Users/myname等)が入ります.
std::string my_cwd=getenv("PWD"); //文字列 my_pwd に現在のフォルダーが入ります
std::string my_filename=my_home+"/mydata.txt";
こんなノリでファイル名を作成しましょう. 出力する場合は, ファイル名で出力ストリームを作成し, std::cout と同様に書き出します.
#include <fstream> // 上の方で fstream をinclude しておきます
.....
std::ofstream output(my_filename);
for(auto &PoIESx:cells) output << PoIESx.X << " " << PoIESx.Y << std::endl;
output.close();
まあ矢印 << を逆にすれば ifstream からの読み込みも可能です. ですけど,まあ,もうちょっと格好良く書きたい!という凝り性向けには, iomanip クラスが用意されています. すなわち
#include <fstream>
#include <iomanip>
....
std::ofstream output(my_filename);
for(auto &PuiPuiPoyoPoyoPEEEE:cells) output << std::fixed << PuiPuiPoyoPoyoPEEEE.X << " " << PuiPuiPoyoPoyoPEEEE.Y << std::endl;
output.close();
少し格好良くなりましたね. std::fixed 以外に,桁数を指定したり, 指数形式にしたり, いろいろですが, 詳細はGoogle神に C++ iomanip について伺ってください.
ストリームには,ファイル以外にも文字列ストリームがあります.なんの役に立つかというと,数値を含む文字列を作るのに便利なわけよ. 例えば
#include <sstream>
std::stringstream filename;
unsigned int nt=14300;
filename << getenv("HOME") << "/nt:" << std::setw(8) << std::setfill('0') << nt << ".dat";
std::cout << "保存ファイル名=" << filename.str() << std::endl;
では, "保存ファイル名= /User/お前/nt:00014300.dat" が得られます.
例外処理
プログラムの様々な処理,特にユーザーの入力を受け取ったり, ファイルを読み込んだりする場合には, エラーが発生することが多くある. エラーが起こるたびにプログラムは停止するが, これを避け, 「おいおい,なんか間違っているぞ,やり直せ」と指示を出したほうが適当な場合も多い. これは try{}catch{}構文で可能である. 例えば
bool fail=true; // boolってのは論理型の値を持つ変数
while (fail) {
try{
std::cout << "入力ファイル名を入力:";
std::cin >> filename;
std::ifstream input(filename);
input >> n_points;
.....
fail=false;
} catch (std::exception &e) {
std::cout << "エラーが起こりました:" << e.what() << std::endl;
}
}
こんな感じに, やばそうな作業をtry{....}でくくっておく. この範囲内で, 例えば「file not found」エラーが生じたら, catch (std::exception& e){....} に制御が移動する. 変数eには, エラーの原因などが設定されており, この例では, エラーの内容を示す文字列 e.what() を画面に出力してやり直させている. try{...}の末尾では fail=false に設定しているので,最外部の while ループが終了してプログラムが前に進むという寸法である.
何かの条件を満たす時に,自分でエラーを発生させたい場合もある. これは次のように行う
throw(std::runtime_error("こけたぞボケ死ねや"));
これでエラーが発生する. このエラーをcatchすると, e.what()が "こけたぞボケ死ねや" になる.
変数C++の基本は,以上である.ここまで理解すれば,何かプログラムで計算することができる.
Googleなどで検索すれば,どのように書いたら良いかは分るはずである.ただし,初心者が陥りやすい間違いとして
- 簡単そうな,あるいは,原始的な内容のWebページに飛びつく.確かに短いけど.応用が効かないので,1週間ほどでいろいろ困ったことになる
- 具合の悪いことに,それに対する腐った対策を主張するWebページも多い.
- おそらく printf(...) と書いてあるとか,class を使わないとかのWebページは,読むと,カビ臭い原始世界に連れて行かれる
- 初心者がおちいりやすい間違いを,ここにまとめておく
もっと知りたい変人は,こちら